기계학습 분야에는 이상치(outlier)를 탐지하는 다양한 알고리즘이 제안되어 있지만, 알고리즘마다 특성이 있기 때문에 이를 잘 알아두어야 문제 풀이에 적합한 기계학습 알고리즘을 선택할 수 있습니다. 이번 절에서는 데이터 기반 의사결정에 광범위하게 사용되는 의사결정나무(Decision tree)를 이용하여 이상탐지를 수행하는 방법을 설명합니다.
이상치는 정상치에 비해 매우 다른 특징을 가진 데이터를 의미합니다. 일반적으로는 이상치를 찾기 위해 정상치를 학습하고, 정상치와 달라보이는 이상치를 추출합니다.
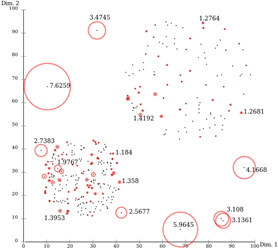
가장 쉽고 간단하게 생각할 수 있는 방법은 통계적으로 평균과 표준편차를 구해서, 이와 크게 벗어나는 값을 이상치로 취급하는 방법입니다. 여기서 더 나아가 다차원 데이터를 취급할 때는 군집 기반의 방법론을 주로 사용합니다. 아래의 도표는 LOF (Local Outlier Factor) 알고리즘이 군집에서 멀리 떨어진 값을 이상치로 계산한 예시입니다.
이러한 기존 방법론의 가장 큰 문제는 1) 정상치를 모두 고려해야 하므로 계산 부하가 크다는 점, 2) 매번 정상치를 프로파일링해서 이상치를 계산하므로 모델을 생성하고 재활용하기 어렵다는 점입니다. Isolation Forest 기계학습 알고리즘은 기존 방법론과 다르게, 이상치 기준을 모델로 생성하는 방법론을 제시합니다.
공간분할 기반 이상탐지
아래의 그림은 2차원 데이터를 대상으로 Isolation Forest의 동작을 시각적으로 보여줍니다.
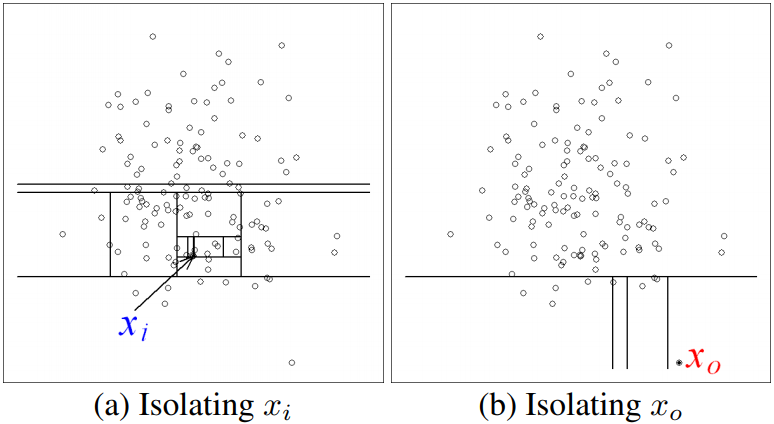
Isolation Forest 알고리즘은 랜덤하게 차원을 선택해서 임의의 기준으로 공간을 분할합니다. 군집 내부에 있는 정상치 Xi의 경우 공간 내에 한 점만 남기고 완전히 고립시키려면 많은 횟수의 공간 분할을 수행해야 하지만, 군집에서 멀리 떨어진 이상치 Xo는 적은 횟수의 공간 분할만으로 고립시킬 수 있습니다.
공간분할은 차원과 기준 값으로 표현할 수 있으므로, 여러 번의 공간분할은 의사결정나무 (Decision Tree) 형태로 표현할 수 있습니다. 정상치일수록 완전히 고립시킬 수 있을 때까지 의사결정나무를 깊숙하게 타고 내려가야 합니다. 반대로 이상치의 경우, 의사결정나무의 상단부만 타더라도 고립될 가능성이 높습니다. 이런 특성을 이용하면 의사결정나무를 몇 회 타고 내려가야 고립되는가를 기준으로 정상치와 이상치를 분리할 수 있습니다.
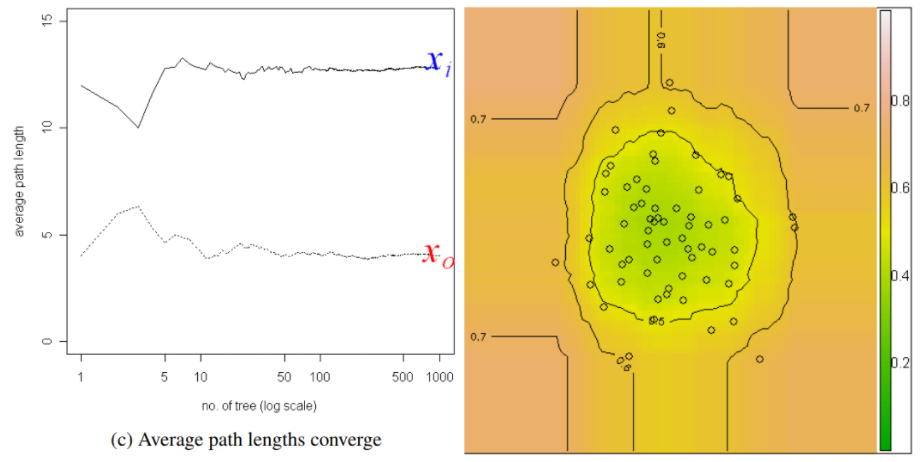
이런 의사결정나무를 여러 개 모아서 앙상블 모델을 만들면 왼쪽 그래프처럼 안정적인 이상지수(score)를 산출할 수 있습니다. 논문에서는 약 50개에서 100개 정도의 의사결정나무를 이용하면 이상지수가 안정화된다는 점을 언급하고 있습니다. 오른쪽 그래프는 등고선 형태로 군집의 경계에 해당하는 점들은 0.5의 이상지수를 가진다는 사실을 보여주고 있습니다. 이상지수는 0~1 범위로 정규화되므로, 일반적으로 0.5보다 크고 1에 가까울수록 이상치로 정의할 수 있습니다.
이상탐지 수행 성능
Isolation Forest는 군집기반 이상탐지 알고리즘에 비해 월등한 실행 성능을 보입니다. 군집기반 이상탐지 알고리즘의 경우, 자기 자신을 제외한 나머지 모든 인스턴스에 대한 유클리디안 거리를 계산해야 하므로 O(N2)의 수행시간이 필요합니다. 반면, Isolation Forest는 일부 데이터를 샘플링하여 의사결정나무 모델을 생성하고 이를 이용하여 이상탐지를 수행하므로 O(logN)의 수행시간이면 충분합니다.
또 하나는 정확성에 대한 부분인데, 이상탐지 분야에서 해결하기 어려운 문제는 Swamping과 Masking이라 불리는 현상입니다. Swamping은 정상치가 이상치에 가까운 경우 이상치로 잘못 분류하게 되는 현상이고, Masking은 이상치가 군집화되어 있으면 정상치로 잘못 분류하게 되는 현상입니다.
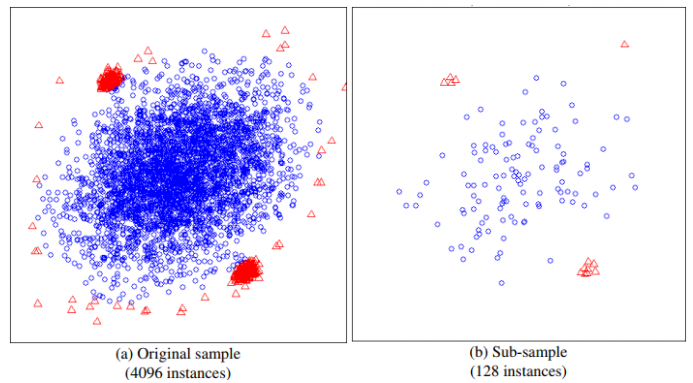
Isolation Forest는 전수 데이터를 이용하지 않고 일부 데이터만 샘플링해서 모델을 생성하기 때문에, 상대적으로 이런 오류에 강건한 특성을 가지게 됩니다. 위의 도표는 이상치 군집과 정상치 군집이 가까이 있을 때, 샘플링이 어떻게 이러한 문제를 극복하는지 시각적으로 보여주고 있습니다.
로그프레소의 활용
로그프레소에서는 기계학습을 쿼리로 수행할 수 있을 뿐 아니라, 스트림 쿼리에 이미 생성된 기계학습 모델을 배포(Deploy)하여 밀리초 이내의 실시간 이상탐지를 수행할 수 있도록 지원합니다.
예를 들어, 이상금융거래시스템(FDS)은 고객정보, 거래정보, 단말정보 등 다차원 데이터를 이용하여 이상탐지 모델을 생성하고 이를 기반으로 0.1초 이내에 실시간 탐지를 수행합니다. 아래는 실제 환경과 유사한 거래 데이터를 가상으로 생성하여 만든 모델링 데모입니다. 이 중에서 거래시각, 고객연령, 연속이체횟수 특성의 분포를 살펴보면 다음과 같습니다.
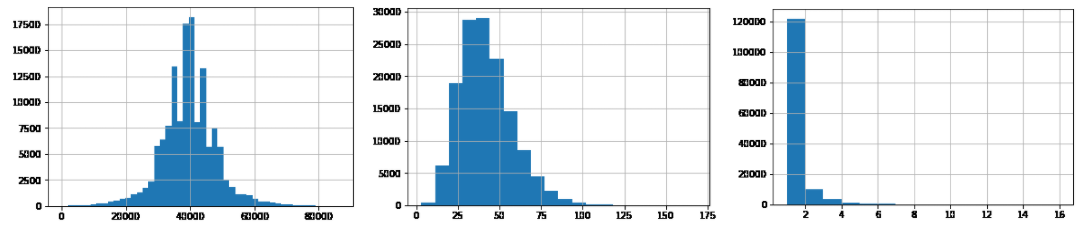
거래시각은 0-86400초 범위의 값, 연령은 0-100 범위의 값, 연속이체횟수는 0-16 범위의 값을 가지고 있습니다. anomalies 쿼리를 사용하면 서브쿼리 결과를 이용하여 Isolation Forest 모델을 즉시 생성하고 이를 이용하여 스코어링을 실행할 수 있습니다.
table transaction
| anomalies _time, age, cnt [ table transaction ]
| eval category = if(_score >= 0.7, "outlier", "normal")
3차원으로 시각화하면 아래와 같이 색상으로 분리된 정상 거래와 이상 거래를 확인할 수 있습니다.
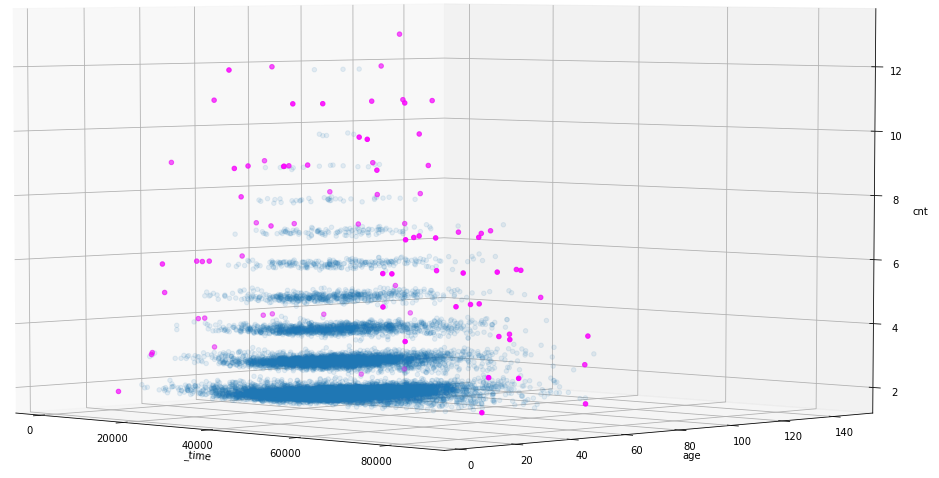
위의 예시는 설명을 위해 극단적으로 단순화한 모델이며, 실제로는 수집 데이터 원본 뿐 아니라 CEP (Complex Event Processing) 기술을 통해 생성된 다양한 특성 값의 분포와 영향력을 비교하고 가공하는 과정을 거치게 됩니다.
기존의 룰/시나리오 기반 탐지 모델은 각각의 차원에 대해 임계치를 정의하고 조합했지만, 기계학습을 이용한 이상탐지는 다차원으로 데이터를 분석하고 경계면을 자동 생성함으로써 더 정교한 탐지를 수행할 수 있습니다.
레퍼런스
- Liu, Fei Tony, Ting, Kai Ming and Zhou, Zhi-Hua. "Isolation forest." Data Mining, 2008. ICDM'08. Eighth IEEE International Conference on Data Mining.
- Liu, Fei Tony, Ting, Kai Ming and Zhou, Zhi-Hua. "Isolation-based anomaly detection." ACM Transactions on Knowledge Discovery from Data (TKDD) 6.1 (2012)


