로그프레소 소나 4.0.2312.0 버전이 출시되었습니다. 이 버전은 많은 분들이 기다려 온 앱 관리 기능, 로그프레소 CTI 피드, 클러스터 기반 룩업 및 예약된 쿼리, 센트리 자동 설치 기능을 포함합니다.
앱 관리 인터페이스

로그프레소 스토어는 이제 100종이 넘는 로그프레소 앱을 지원합니다. 로그프레소 앱을 설치하면 수집기, 파서, 로그 스키마, 데이터셋, 위젯, 대시보드, 탐지 시나리오 등 모든 객체가 자동으로 구성되므로, 로그프레소 플랫폼을 설치한 당일 모든 장비 연동 작업을 완료할 수 있습니다.
그러나 로그프레소 셸을 통해 로그프레소 앱을 설치하는 작업은 너무 번거로운 일이었습니다. 특히 10대 이상의 로그프레소 소나 클러스터를 운영하는 경우, 모든 노드에 앱을 설치하는 작업은 많은 시간을 소모합니다.
이제 웹 콘솔에서 앱을 업로드하면 모든 노드에 자동으로 앱이 설치되고, 앱을 업데이트하면 앱으로 설치된 모든 객체가 자동으로 업데이트됩니다. 보안 장비의 펌웨어가 업데이트되면 새로운 로그 유형이 추가되는 경우가 흔한데, 수집 설정을 일일이 변경하지 않아도 앱 업데이트만으로 관련된 설정이 자동으로 업데이트됩니다.
로그프레소 CTI 피드
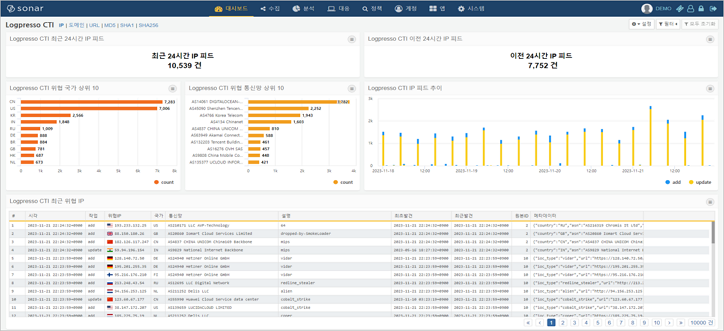
새로 출시된 로그프레소 CTI 서비스는 IP 주소, 도메인, URL, MD5, SHA1, SHA256 침해지표를 제공하며, 로그프레소 플랫폼과 완전히 통합됩니다.
대부분의 CTI 서비스는 API 호출 건수 기반으로 과금하기 때문에 비용 및 성능 이슈가 존재하며, 이미 탐지된 경보에 대해 2차 검증만을 수행할 수 있습니다. 로그프레소 CTI 서비스는 일 20억 건 이상의 방화벽 로그에 대해서 실시간 전수 검사를 실행할 수 있는 성능을 제공합니다. 즉, 악의적인 행위를 하지 않더라도 네트워크 접근 단계에서 탐지 및 대응을 수행할 수 있습니다.
센트리 자동 설치
그동안 수십 대 혹은 수백 대의 에이전트를 설치하는 작업은 상주 엔지니어 투입이 요구될 정도로 힘든 일이었습니다. 이 때문에 대형 사이트의 경우 전용 인스톨러를 빌드하여 사용하기도 했습니다. 이 뿐만 아니라, 초기 구축 후 수 년이 지나 인증서가 만료되면 각 서버를 순회하면서 인증서를 일일이 교체하는 작업을 수행해야 했습니다.
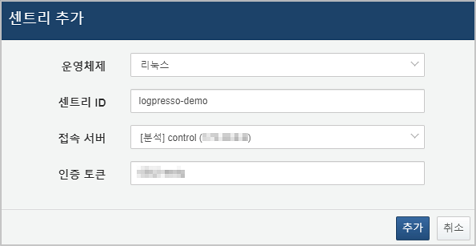
이제 웹 콘솔에 표시되는 스크립트를 복사하여 관리자 터미널에 붙여넣고 실행하기만 하면 로그프레소 센트리 설치가 완료됩니다.
단순화된 설치 과정으로 설정 누락 등 휴먼 에러 가능성이 원천적으로 사라지고, 인증서도 중앙집중적 방식으로 재발급하거나 파기할 수 있어 유지보수성이 매우 향상되었습니다.
클러스터 기반 룩업
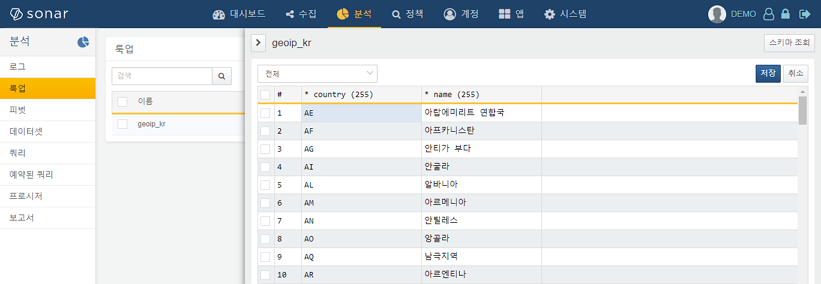
로그프레소 소나의 클러스터 설계에 맞춰 룩업 기능이 새로 개발되었습니다:
- 클러스터 동기화
- 이전에는 로그프레소 노드 단위로 룩업 데이터가 관리되었기 때문에 클러스터 환경에서 데이터 일관성을 유지하는데 어려움이 있었습니다. 이제 웹 콘솔에서 데이터를 편집하면 클러스터 전체에 자동으로 동기화됩니다.
- 데이터량 제한 해제
- 지금까지 JDBC 룩업 이외의 룩업 엔진은 힙 메모리에 모든 레코드를 유지했기 때문에 데이터 량에 한계가 있었습니다. 그러나 이제 디스크에 데이터를 유지하고 자주 참조되는 데이터를 캐시하는 방식으로 개선되어 100만 건 이상의 레코드도 문제 없이 처리할 수 있습니다.
- API를 통한 실시간 업데이트 지원
- 일반적으로 룩업 데이터는 원본이 외부에 존재하므로 데이터를 동기화할 필요가 있습니다. 이전에는 주기적으로 룩업 데이터를 조회하여 동기화하기 때문에 변경사항이 뒤늦게 반영되는 한계가 있었습니다. 이제 룩업 REST API가 지원되므로 외부에서 룩업 데이터 변경이 발생할 때마다 실시간으로 동기화를 수행할 수 있습니다.
클러스터 기반 예약된 쿼리
마찬가지로, 예약된 쿼리 역시 로그프레소 소나의 클러스터 설계에 맞추어 새로 개발되었습니다:
- 클러스터 단위의 실행
- 이전에는 예약된 쿼리가 로그프레소 노드 단위로 실행되었기 때문에, 각 노드마다 예약된 쿼리를 설정해야만 하는 불편이 있었습니다. 새 기능은 클러스터의 특정 유형의 서버 집합에 대해 예약된 쿼리를 일괄 실행할 수 있습니다.
- 워크플로우 지원
- 이전 세대의 제품은 예약된 쿼리와 워크플로우가 개별적인 기능이었습니다. 새 기능은 다른 예약된 쿼리의 완료, 성공, 실패에 따라 특정한 쿼리가 실행되도록 설정할 수 있으므로 더 직관적으로 동작합니다.
- 실행 모니터링
- 이전 세대의 제품은 쿼리 로그를 별도로 검색하지 않으면 예약된 쿼리가 언제 마지막으로 실행되었는지, 얼마나 소요되었는지 파악하기 어려웠습니다. 새 기능은 목록에서 쿼리 실행 상태를 바로 확인할 수 있습니다.
맺음말
이 외에도 많은 기능들이 개선되었습니다. 4.0.2312 릴리스 노트에서 세부사항을 확인해보세요!


